Depois de desenhar o diagrama, as variáveis endógenas e exógenas devem ser conectadas entre si com uma seta unidirecional . Os erros das variáveis endógenas são incluídos no modelo clicando na variável com o ícone "Adicionar uma variável única a uma variável existente". Plugins → Nomeie variáveis não observadas para nomear essas variáveis (se a nomeação não for feita, um aviso aparecerá durante a fase de análise). Apresenta-se seguidamente um modelo estrutural de exemplo.

Uma das hipóteses do modelo de equações estruturais apresentado na Figura 11 é "A ligação entre a atenção plena dos pais e a regulação emocional dos filhos é mediada pela atenção plena no casamento". Com base nessa hipótese, a atenção plena dos pais prevê a atenção plena no casamento e a atenção plena no casamento prevê a regulação emocional de seus filhos. Assim, pode-se dizer que a atenção plena dos pais prevê a regulação emocional de seus filhos através da atenção plena no casamento. Se você tentar analisar o modelo estrutural na figura, verá um aviso sobre a não inclusão de termos de erro. Portanto, adicionar um termo de erro às variáveis endógenas (dependentes) é importante.
Uma vez concluído o modelo estrutural, seguem-se as etapas de teste do modelo de medição descrito na seção anterior. Em primeiro lugar, deve examinar-se se as estimativas dos parâmetros são estatisticamente significativas. Na janela "Saída", selecione "Estimativas" na lista à esquerda. Efeitos diretos, indiretos e totais podem ser vistos na tela que se abre após a seleção. Coeficientes de caminho significativos são importantes para o ajuste geral do modelo (Baron & Kenny, 1986). O coeficiente de regressão deve ser verificado quanto à significância dos coeficientes de trajetória. Para examinar se esses valores são significativos ou não, o valor de p de cada um deles deve ser examinado. Se este valor for inferior a .05, pode-se dizer que o coeficiente de caminho é significativo. Abaixo está uma imagem de saída de amostra mostrando os coeficientes de regressão e coeficientes de regressão padronizados.
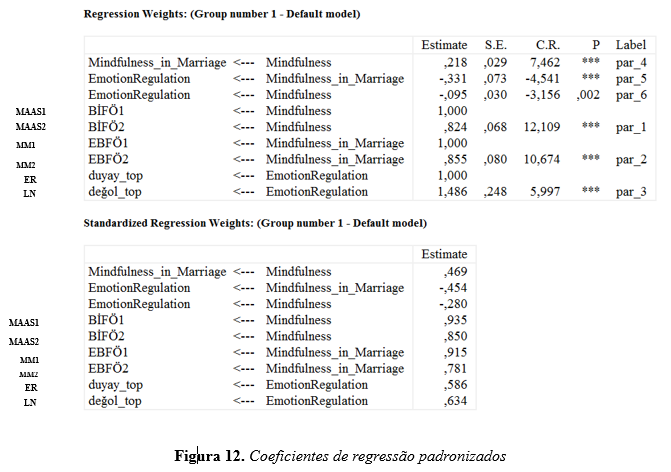
Na Figura 12, em primeiro lugar, deve-se examinar se os coeficientes de caminho são significativos ou não na tabela "Pesos de Regressão". A tabela "Pesos de Regressão Padronizados" deve ser examinada quanto aos coeficientes de caminho. Embora seja desejável para o modelo que todos os caminhos sejam significativos, a não significância do caminho entre a variável dependente e a variável independente não é vista como um problema, uma vez que reflete a força da variável mediadora na relação. Depois de avaliar se os coeficientes de caminho são significativos ou não, a bondade dos índices de ajuste fornecidos sob o título "Model Fit" no arquivo de saída são examinados e avaliados de acordo com os critérios de corte dos índices de ajuste. Os modelos com melhor ajuste aos dados são indicados pela bondade dos índices de ajuste (Smith & McMillan, 2001). A bondade dos índices de ajuste é avaliada no âmbito dos critérios de corte dos índices de ajuste recomendados por Schermelleh-Engel et al (2003) e apresentados na Tabela 1. Em resultado destas avaliações, o modelo estrutural é aceite, rejeitado ou modificado.



 Após o cumprimento do pressuposto de normalidade, o modelo estrutural é construído de acordo com as hipóteses da pesquisa. A variável latente e suas variáveis observadas são desenhadas no espaço de trabalho à direita, clicando no ícone do menu do lado esquerdo. As variáveis observadas são selecionadas a partir da janela aberta clicando no ícone e transferidas para a tela arrastando e soltando com o mouse. As variáveis latentes são representadas por elipses, enquanto as variáveis observadas são representadas por retângulos. Os valores de erro associados às variáveis observadas também são mostrados como elipses e todas as variáveis observadas têm valores de erro. A figura abaixo mostra a variável latente, as variáveis observadas e os valores de erro dessas variáveis observadas na janela principal do AMOS Graphics.
Após o cumprimento do pressuposto de normalidade, o modelo estrutural é construído de acordo com as hipóteses da pesquisa. A variável latente e suas variáveis observadas são desenhadas no espaço de trabalho à direita, clicando no ícone do menu do lado esquerdo. As variáveis observadas são selecionadas a partir da janela aberta clicando no ícone e transferidas para a tela arrastando e soltando com o mouse. As variáveis latentes são representadas por elipses, enquanto as variáveis observadas são representadas por retângulos. Os valores de erro associados às variáveis observadas também são mostrados como elipses e todas as variáveis observadas têm valores de erro. A figura abaixo mostra a variável latente, as variáveis observadas e os valores de erro dessas variáveis observadas na janela principal do AMOS Graphics. 





