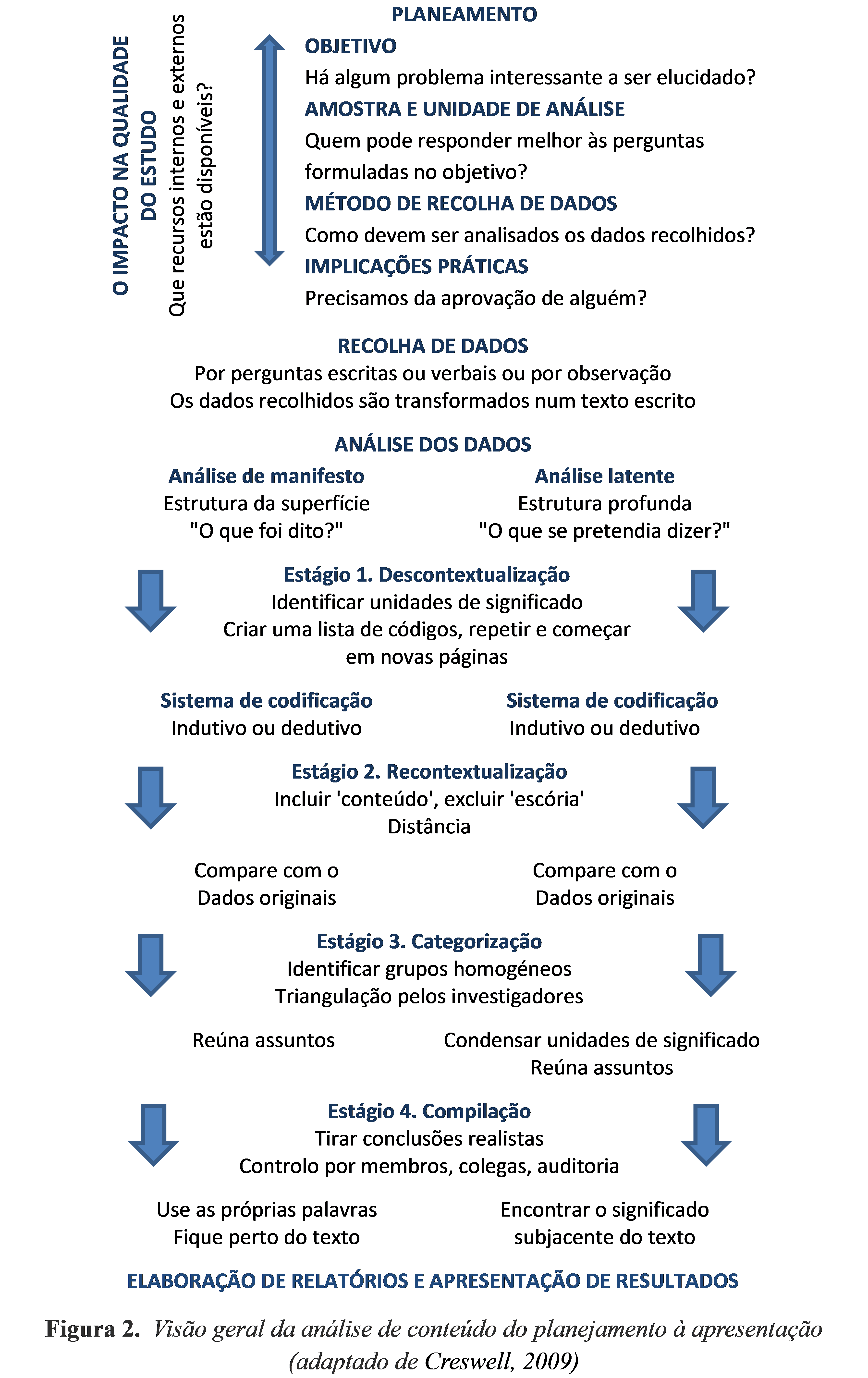
Uma vez estabelecidas as categorias, inicia-se a análise e o processo de escrita. Uma diferença entre os vários métodos de análise qualitativa é a forma como o investigador se relaciona com o processo de análise em si e se adapta aos resultados. Ao realizar a análise qualitativa de conteúdo, o investigador deve considerar os dados coletados de uma perspetiva neutra e considerar sua objetividade. No entanto, o pesquisador tem uma escolha entre o nível manifesto e latente, e a profundidade da análise dependerá de como os dados são coletados. Numa análise de manifesto, o investigador trabalha desta forma gradualmente através de cada categoria identificada, e numa análise latente através dos temas. Em uma análise de manifesto, o pesquisador utiliza frequentemente as palavras dos informantes, e eles permanecem conscientes da necessidade de remeter ao texto original. Desta forma, é possível ficar mais próximo dos significados e contextos originais (Burnard, 1991). Em contrapartida, uma análise latente convida o pesquisador a mergulhar em alguma medida nos dados para identificar significados ocultos no texto. Para cada categoria ou tema, o pesquisador escolhe unidades de significado apropriadas apresentadas no texto em execução como citações. Independentemente da forma de análise, o investigador pode apresentar um resumo de temas, categorias/subtemas e subcategorias/sub-títulos como uma tabela para permitir ao leitor obter uma rápida visão geral dos resultados. Além disso, convém apresentar um exemplo do processo de análise. Existe também a possibilidade de adicionar informação através da realização de alguma quantificação em que as subcategorias e categorias são contadas. Isso normalmente não é feito em outros métodos de pesquisa qualitativa. No entanto, quase tudo pode ser contado em mensagens escritas – como palavras, caracteres, parágrafos e conceitos – dependendo do foco do estudo. Ao combinar a quantificação com uma abordagem qualitativa, a magnitude dos fenómenos individuais estudados aparece mais claramente (Berg, 2001). No entanto, as variáveis não podem ser classificadas, uma vez que nem todos os informantes tiveram a oportunidade de discutir todos os fenômenos que o pesquisador finalmente conta.
Finalmente, o pesquisador deve considerar como os novos achados correspondem à literatura e se o resultado é razoável e lógico (Burnard, 1991; Morse e Richards, 2002). Para validar o resultado e fortalecer a validade do estudo, o pesquisador pode realizar uma validação do entrevistado, uma verificação do membro, o que significa que o pesquisador volta aos informantes e apresenta os resultados para alcançar a concordância (Burnard, 1991; Catanzaro, 1988). No entanto, existe um intervalo de tempo entre a recolha e a análise dos dados. Esta abordagem constitui, portanto, um risco por várias razões, uma das quais pode ser a possível falta de fiabilidade da memória dos informadores. Outro risco é que os informantes têm tendência a negar aspetos menos atraentes do seu comportamento. Além disso, como o pesquisador muitas vezes cria uma compreensão holística mais profunda do fenômeno estudado, os informantes podem não reconhecer como os dados são apresentados. Tendo isso em mente, é melhor para o pesquisador obter alguma confirmação sobre o conteúdo dos informantes em conexão com a coleta de dados (Catanzaro, 1988). Outra maneira de aumentar a validade é que um colega não envolvido no estudo, ou um auditor de inquérito, leia o texto original e os resultados e, em seguida, julgue se eles são razoáveis ou não (Burnard, 1991; Catanzaro, 1988). No entanto, é obviamente difícil para uma pessoa independente familiarizar-se com a codificação de outra pessoa (Bengtsson, 2016, p. 13).