Globally, a meta-analysis starts by formulating the research questions. The research questions should be tested based on the published studies. The published studies need sufficient information to calculate the effect sizes, which is essential for a meta-analysis. Comprehensive inclusion and exclusion criteria are established to determine which studies qualify for inclusion in the meta-analysis. Once the effect sizes and study characteristics are gathered, the data can undergo statistical analysis. The subsequent step involves interpreting the results and preparing reports to share the findings (Cheung, 2015).
Conducting a meta-analysis entails predefined eligibility criteria, exposure variables, primary and secondary outcomes of interest, and an analysis plan. Proper indications and methodologies, minimising bias risk, and avoiding misleading conclusions are important. Meta-analysis is acknowledged as the optimal approach for objectively assessing and studying the evidence pertaining to a specific issue, furnishing a high level of evidence and contributing to the advancement of knowledge.
Sen and Yildirim (2022) organise the mandatory process of a meta-analysis into the following steps:
- Formulating the Research Question and Team: The process begins with developing a straightforward research question and assembling a research team.
- Designing and Executing a Search Strategy: A systematic search strategy is crucial to finding all available evidence from published and unpublished sources.
- Screening and Extracting Data: A decision should be made on selecting appropriate studies from the collected studies. Relevant studies are screened, and data is extracted from these studies.
- Critical Appraisal and Analysis: Quality control/sensitivity analyses should be conducted. Each study should be critically appraised for potential biases, and the evidence should be assessed and analysed.
- The effect size for the chosen studies must be determined and computed separately for each study.
- The data needs to be pooled, and a summary statistic and a confidence interval must be computed.
- Additional analyses (heterogeneity, publication bias) should be done.
- Moderator analyses for moderator variables should be performed.
- Interpret the results and draw conclusions (inferences) based on them. Reporting and Disseminating Findings: The steps mentioned above should be reported together with the meta-analysis findings.
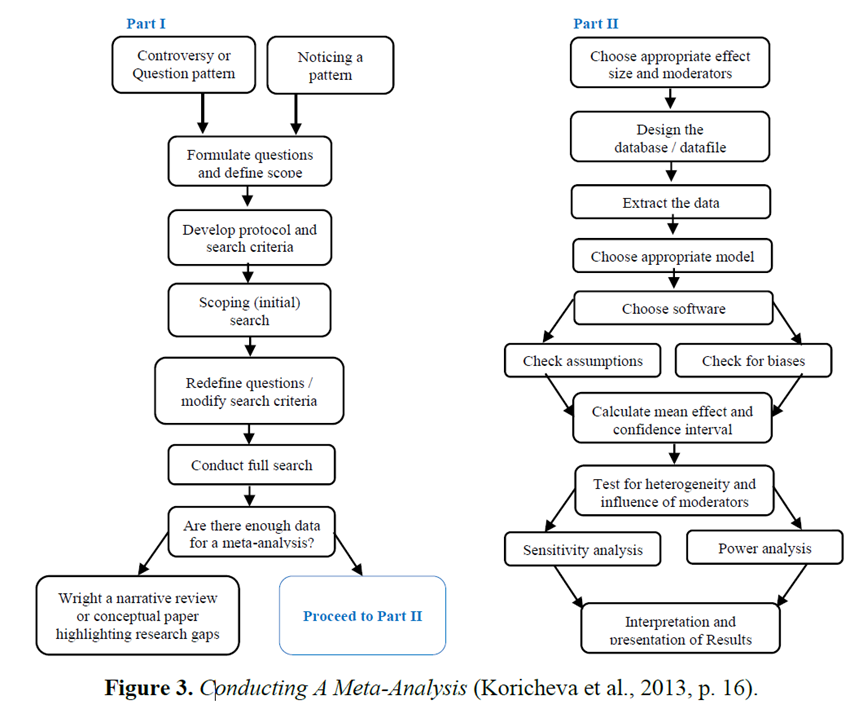
Figure 3 depicts the beginning phase of developing a question and methodically searching for relevant studies in the primary literature (Part I), as well as the phase where you gather data from publications, conduct statistical analyses, and present and explain your findings (Part II).
Meta-analysis methods have advanced notably over the last few years (Irsova et al., 2023). Performing a meta-analysis is conceptually no different from an empirical study because sometimes statistical problems bog you down. However, researchers usually design a study with their statistical abilities in mind or follow an established design that allows them to replicate a standard analytic approach. The difference between a good and a bad empirical study often boils down to whether an interesting question is being asked and the quality and quantity of the data collected using an unbiased sampling technique. The same principles apply to meta-analysis, where recently developed techniques allow for solid conclusions even when facing challenges in the underlying empirical literature (Irsova et al., 2023).
Despite the linear appearance of the process outline (Fig. 2), there is often uncertainty leading to certain steps being repeated. During Part I, the researcher may find it necessary to iterate through multiple cycles of scoping searches, adjusting study questions, and modifying the protocol and search criteria until confident that a comprehensive search will yield the desired results. A short description of what each step involves each step in the process.