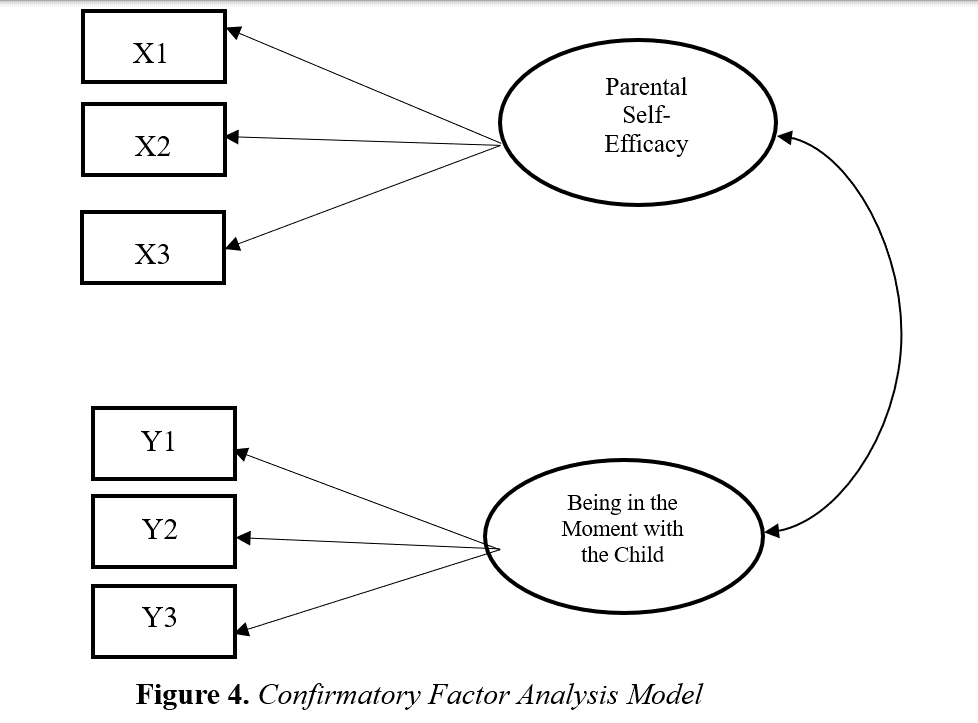
Characteristics like attitudes, IQ, personality traits, and socioeconomic status that are not directly observable are referred to as latent variables in the social and behavioral sciences (Yuan & Bentler, 2007). Ellipses are used as a visual representation of latent variables in AMOS analysis. It is necessary to establish measurable behaviors that are assumed to reflect this latent variable because latent variables can not be directly assessed. Thus, observed variables are used to gather information on latent variables. Observed variables, also known as indicator variables, are visually represented by rectangles or squares (Schreiber et al., 2006). Scales used in research to measure a certain emotion, thought or behavior are examples of observed variables. For example, Mindfulness in Marriage Scale (Erus & Deniz, 2018) is a latent variable, and sub-dimensions of the scale formed by the scale items are observed variables that make the latent variable observed. Scale items are brought together to make the concept of mindfulness in marriage observed. Figure 1 shows an example of observed and latent variables.
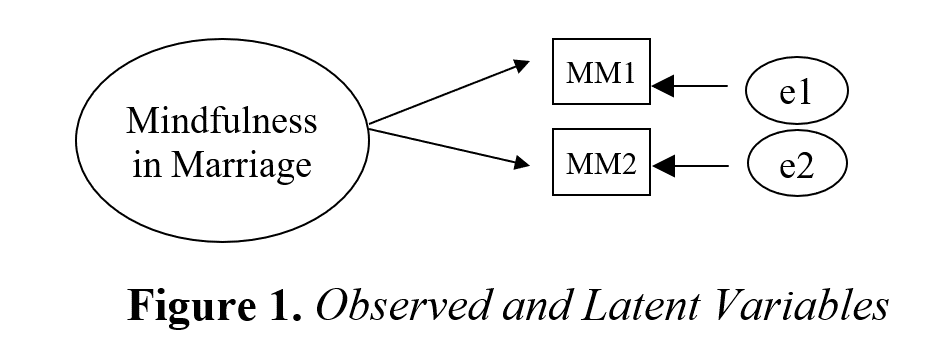
As seen in Figure 1, MM1 and MM2 sub-dimensions are observed variables and Mindfulness in Marriage is a latent variable. MM1 and MM2 are taken as indicators of Mindfulness in Marriage. Mindfulness in Marriage Scale is unidimensional, but in order to create Structural Equation Modeling, the scale was divided into two sub-dimensions by “parceling method”. If there are no sub-dimensions of a scale, dimensions should be created by parceling method for Structural Equation Modeling. In order to analyze latent variables, the parceling method involves building “item plots” based on the totals of the responses to various items (Russell et al., 1998). An aggregate indication called a parcel is made up of the mean of two or more items, behaviors or answers (Little et al., 2002). There are several techniques for parceling, including exploratory factor analysis (for more information about parceling; see Matsunaga, 2008). Random parceling is one of the easiest ways to constructing parcels. The goal of random parceling is to assign each item to a parcel group at random, without change. There can be two, three, or four parcels constructed, depending on the number of items that need to be assigned (Little et al., 2002). Alternatively, you can take the sum of the even numbered items of the scale as one parcel and the sum of the odd numbered items as the other parcel. It should be noted, however, that a latent variable must have at least two observed variables. However, e1 and e2 are error terms. The influence of measurement error on the observed variables is shown by the one-way arrows linking the error terms to the variables.