
Comprehending the role and significance of research designs is crucial for effective research. The design encompasses the entire research process, from framing the question to analysing and reporting data.
Two fundamental research questions exist: descriptive research, which explores what is happening, and explanatory research, which focuses on why things are happening.
Descriptive research can be advantageous, especially when exploring new areas, as it can provoke "why" questions for explanatory research. Explanatory research involves developing causal explanations that argue that a specific factor affects a particular phenomenon. For instance, gender may affect income levels. However, the complexity of causal explanations may vary, and hidden or unmeasured variables may be at play.
It is important to note that people often mistake correlation for causation. When two events are linked, it does not necessarily imply that one causes the other. The link between them may be coincidental rather than causal. Therefore, it is crucial to understand the distinction between correlation and causation to conduct effective research.
Aaker et al. (2013) organise the process/design of a study as shown in Fig. 6. It all starts with specifying the Research Question, that is, the problem that the project will try to solve and the knowledge to which it will contribute or initiate.
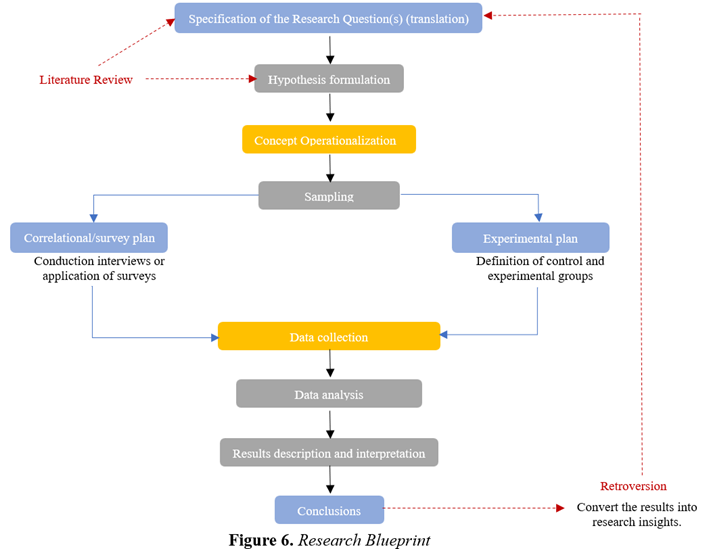
Directly resulting from the literature review, it must immediately be "translated" into research questions, that is, hypotheses that will determine what will be measured, from what sources of information and with what methodologies. Research hypotheses are systems of variables whose sets, although only partially exhaustive, cover the main dimensions of the phenomenon under analysis. They also clarify the relationships proposed between such variables that need testing. With this, the following very relevant and demanding task is operationalising (making measurable) the variables whose relationships will be tested (scales).
Once the research question has been specified, the concepts (variables), latent or directly observable, have been defined and whose relationships will be tested, and the measures that capture them have been specified, it is essential to determine which units of information will contain the required information (secondary or primary).
Quantitative studies (experimental/non-experimental) must also define the sampling method (random/non-random) that will be applied to this "population" and the size and characteristics of the groups (non-experimental; experimental; control) that will be heard.
With this knowledge, the researcher must decide which concrete information collection plan to adopt: correlational/survey (cross-sectional; longitudinal) or experimental.
Collecting information (questionnaire) is complex, susceptible to adding "errors," and dependent on the researcher's experience. For all these reasons, it is advisable to use scales that have already been validated in previous studies whenever possible, reinforcing their reliability and validity.
Once organised information is available, the data will be subjected to adjusted and planned analyses to test the research hypotheses (descriptive, univariate, multivariate, inferential). The results obtained must then be described and interpreted to, in conclusion, be "converted" into an answer(s) to the initial Research Question that triggered the entire process.
